Essay · Music Informatics
What automatic music transcription is
Turning a recording into a score sounds trivial until you try it. What automatic music transcription (AMT) is, why it remains an open problem, and where it sits on the road from audio to symbol.
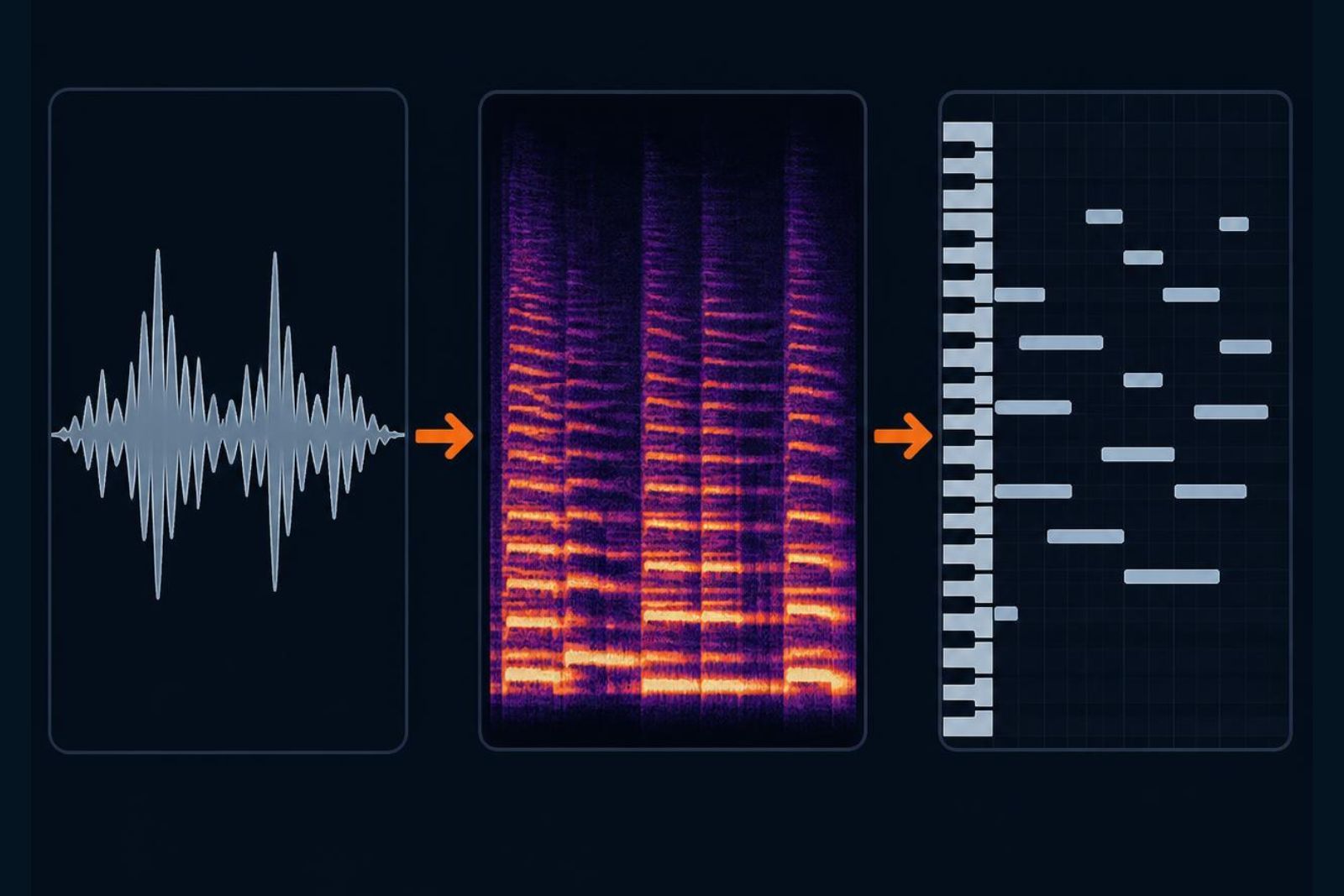
When I explain what part of my research is about, I tend to use a sentence that sounds simple: “I try to get a computer to listen to a recording and write down the score.” The reply is almost always the same — “isn’t that already solved?” It is not. That task has a name, automatic music transcription, and it has spent decades as one of the most stubborn open problems in music computing.
What automatic music transcription is
Automatic music transcription — AMT for short — is the task of converting an audio recording into a symbolic representation: which notes are sounding, when they start, how long they last, and at what pitch. The result can be a score, a MIDI file, or a piano roll, that grid of notes you see in any music editor.
Put another way: AMT is the reverse of what a synthesiser does. A synthesiser starts from instructions and produces sound; transcription starts from the sound and tries to recover the instructions that produced it. And that is where the catch lies, because the way back is neither unique nor clean.
The problem: from air to score
A recording is a continuous signal: a single wave that mixes everything sounding in that instant. A score, by contrast, is discrete and structured: separate notes, each with its pitch and its rhythm. AMT has to cross that gap, and it usually does so on two planes.
The first is the signal plane. Before you can talk about notes, you have to look at the frequencies that make up the sound, and for that the basic instrument is the Fourier transform: it decomposes the wave into its frequencies and lets you draw a spectrogram, a map of how much energy there is at each frequency over time.
The second is the symbolic plane: from that map, deciding where a note begins, what pitch it has, and when it ends. It is the jump from “there is energy around 440 Hz” to “this is an A lasting a quarter note.” That jump is the heart — and the difficulty — of transcription.
Why it is harder than it looks
If only one note sounds at a time, the problem is almost manageable. The complexity explodes with polyphony: when several notes sound at once, their frequencies overlap in the spectrum. A low note and a high one can share harmonics, so the system cannot tell whether it is seeing two notes or a single one with its harmonic series. Separating that mixture is an ill-posed problem: many combinations of notes produce almost the same spectrum.
On top of that comes everything a musician does without thinking and a machine cannot read:
| Challenge | Why it complicates transcription |
|---|---|
| Polyphony | Overlapping frequencies; harmonics shared between notes |
| Timbre | The same A sounds different on a bagpipe, a piano, or a voice |
| Tuning | Not all music uses the even 12-note temperament |
| Ornamentation | Grace notes, slides, and vibrato that are not clean “notes” |
| Flexible rhythm | Human tempo fluctuates; it does not fit a perfect grid |
That is why AMT is not considered solved. Current systems transcribe the piano reasonably well — heavily studied and backed by huge corpora — and struggle with less represented instruments and with music that does not fit the Western mould.
Where AMT fits
Transcription is not an island. It is one of the tasks of Music Information Retrieval (MIR), the field that studies how to extract musical information from audio. And it depends entirely on something unglamorous but decisive: data. A modern transcription system learns from examples — pairs of audio and its correct transcription — so without a well-labelled corpus there is nothing to learn from. That is exactly why I put so much effort into building audio corpora: the quality of the data sets the ceiling on what the model can ever do.
Why it matters to me
There is a personal reason behind all of this. In 2005 Guitar Hero came out and left me fascinated. Even though it was only a game, that plastic guitar working as an interface to the system lit up an idea I have been chasing ever since: the connection between instrument and system. I find it an enormous challenge to find the path that joins musical instruments with computers able to make use of all the information emitted while playing.
That crossing between instrument and system is, for me, where music computing and the musical root truly meet. Not to replace the musician — a transcription never fully captures what happens in a performance — but to have one more tool with which to study, archive, and understand a repertoire that deserves to be documented.
References
The references this article draws on, and where to read further:
- Benetos, E., Dixon, S., Duan, Z., & Ewert, S. (2019). Automatic Music Transcription: An Overview. IEEE Signal Processing Magazine, 36(1), 20–30.
- Benetos, E., Dixon, S., Giannoulis, D., Kirchhoff, H., & Klapuri, A. (2013). Automatic music transcription: challenges and future directions. Journal of Intelligent Information Systems, 41(3), 407–434.
- Müller, M. (2015). Fundamentals of Music Processing: Audio, Analysis, Algorithms, Applications. Springer.
- Klapuri, A., & Davy, M. (Eds.). (2006). Signal Processing Methods for Music Transcription. Springer.
Frequently asked questions
-
¿En qué formato entrega los resultados un sistema de AMT?
Un sistema de AMT no devuelve audio, sino una representación simbólica de lo que ha “escuchado”. El formato depende del uso: MIDI si se quiere reproducir o secuenciar, MusicXML si se busca una partitura editable e imprimible, o un piano roll para visualizar y corregir. Lo habitual es que el resultado pase siempre por una revisión humana, porque ninguna transcripción automática es perfecta. Más contexto en ¿Qué es la transcripción automática de música?.
-
¿Por qué la polifonía complica la transcripción automática?
Si solo suena una nota cada vez, el problema es abordable. Con varias notas simultáneas —polifonía— sus frecuencias y armónicos se solapan en el espectro: una nota grave y otra aguda pueden compartir parciales, así que el sistema no sabe si ve dos notas o una sola con su serie armónica. Como muchas combinaciones distintas producen casi el mismo espectro, separar la mezcla está mal definido. Es una de las razones por las que la AMT sigue sin estar resuelta, sobre todo en instrumentos con bordón como la gaita. Lo desarrollo en ¿Qué es la transcripción automática de música?.